스터디 진행 일시
날짜 : 11월 15일 (목요일) 시간 : 오후 7시 ~ 9시 (2시간) 장소 : 강남 (오프라인) 오늘 함께한 멤버 ❣️ : 준호님 / 은지님 / 요한님 / 유경님 / 소영님/ 근우님 === 스터디 추가 진행 === 날짜 : 11월 16일 (금요일) 시간 : 오후 5시 ~ 10시 (5시간) 장소 : 강남 (오프라인) 오늘 함께한 멤버 ❣️ : 준호님 / 은지님 / 요한님 / 유경님
디자이너 없이 디자인 하는 방법
🙌 소영님의 세미나 🙌
- 소영님이 정리하신 노션
- 팀에 디자이너가 없는데 서비스 런칭을 해야 한다!
- 이럴 땐 보통 아래와 같은 선택지가 있다.
- 외주 디자이너를 고용한다. 👍
- 기획자에게 디자인을 맡긴다. 😟
- 디자인을 전공했던 직원에게 시킨다. 🤯
- 개발자가 디자인 한다. 🤮
이전에는 주로 외주를 맡기거나 정 안되면, 개발자가 디자인을 하기도 했는데, AI의 발전으로 이제는 AI툴을 활용하면 디자이너 없이도 빠르게 시안을 뽑을 수 있게 되었다.
- 요즘 핫한 AI 디자인 툴
- 스치티: 무료, 프롬프트 기반 UI 디자인 생성, 피그마 연동, 제미나이 2.5 기반 고품질 디자인
- 피그마 사이트: 유료(fullseat), 피그마 내 반응형 웹사이트 배포, 오토레이아웃, 템플릿
- 피그마 메이크: 유료(fullseat), 피그마 내 코드 기반 디자인/프로토타입 제작, 클로드4 기반 코드 생성, supabase 연동 가능
- 스티치
- 예산이 적고(무료툴이기 때문에, 그런데 언제 유료가 될지 모름) 디자인 시안을 빠르게 뽑아야할 때 적합한 디자인 시안기 역할로 좋은 것 같다.
- 피그마 사이트
- 프롬프트만으로 꽤 괜찮은 UI 디자인을 순식간에 생성하는 무료 시안 생성기
- 피그마 메이크
- 피그마 내에서 코드 레이어를 통해 인터랙티브 디자인 구현이 가능하며, 코드 생성 정확도가 높은 프로토타입 제작 툴.
- 피그마 내에서 코드 레이어를 통해 인터랙티브 디자인 구현이 가능하며, 코드 생성 정확도가 높은 프로토타입 제작 툴.
MVC1과 MVC2 패턴의 차이점
🙌 요한님의 세미나 🙌
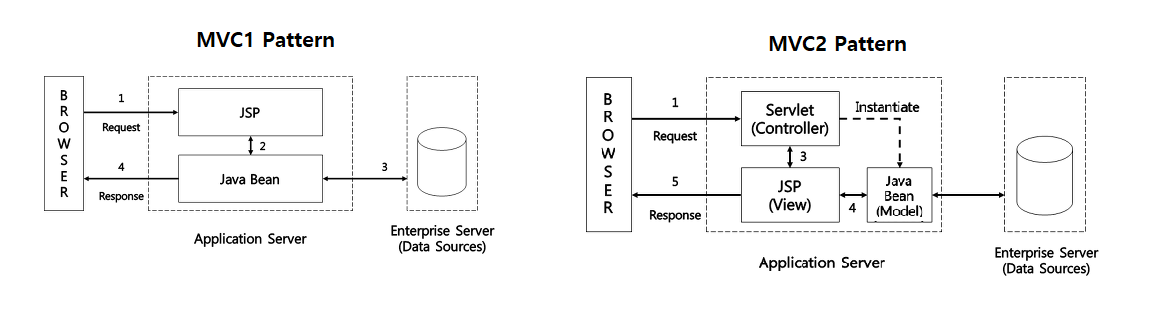
- MVC1은 View와 Controller 로직이 명확히 분리되지 않은 구조로, 화면(View)에서 비즈니스 흐름 제어까지 함께 수행한다.
- View → Model → DB 흐름으로 동작하며, 화면 렌더링 코드와 요청 처리 로직이 혼재하여 책임 분리가 되지 않고 유지보수성이 떨어지는 문제가 있다.
- MVC2는 View와 Controller를 명확히 분리한 구조인데, (Controller → Model → DB → View) 흐름으로, Controller가 모든 요청을 먼저 받아 처리한 후 그 결과를 View에 전달한다.
- 이로 인해 역할이 명확하게 구분되고, 코드 가독성·유지보수성·개발 속도 모두 개선된다.
RAG가 무엇일까?
🙌 은지님의 세미나 🙌
- 은지님이 정리하신 노션
- 왜 RAG가 필요할까 ?
- 우리는 LLM을 사용하면서 아래와 같이 여러 문제점이 부딪히게 된다.
- 지식 최신성 부족(Knowledge Cutoff 문제)
- 모델이 2024년까지 학습된 모델이라면 2025년도의 문서나 지식은 없다.
- 법, 기술들은 시간이 흐르면서 계속 바뀌는 정보이기 때문에 틀릴 확률이 높다.
- Hallucination
- LLM은 모르면 “모르겠습니다” 보다는 “그럴듯한 거짓말”을 생성한다.
- 그~짓말을 하는 이유
- 확률 모델이기 때문이기도 하지만, 학습의 목표가 “정답”이 아니라 “그럴듯함”이기 때문이다.
- 도메인 특화 정보에 접근 불가 (사내 문서)
- 사내 위키나 노션, 메뉴얼, 로그, Q&A 데이터는 사전에 학습된 데이터가 아니다.
- 그래서 “우리 회사 내부 결재 규정에 맞춰 설명해줘”라고 해도, 모델은 자기 파라미터 기준 “그럴듯한 일반 회사 규정”을 말할 뿐…
- 지식 최신성 부족(Knowledge Cutoff 문제)
위에 언급된 LLM 한계를 보안하기 위해 많이 사용하는 대표적인 방법 2가지를 보자. 가장 많이 사용하는 방법은 프롬프트(Prompt) 엔지니어링과 RAG를 많이 사용한다.
- 프롬프트 엔지니어링
- 프롬프트의 구조는 아래와 같이 할 수 있다.
- System Prompt : 모델한테 “역활”과 “행동 원칙”을 정의
- User Prompt : 유저의 실제 요청과 참조 정보
- Assistant Prompt : LLM 의 출력
- “모델이 과거에 이런 식으로 대답했었다” 라는 것에 대한 힌트
- 프롬프트의 구조는 아래와 같이 할 수 있다.
- RAG
- LLM이 외부에 있는 DB를 조회해서 LLM 답변을 개선하는 과정을 말한다.
- 모든 기술이 그러하듯, 시간에 따라 RAG에 대한 패러다임이 변하고 있다.
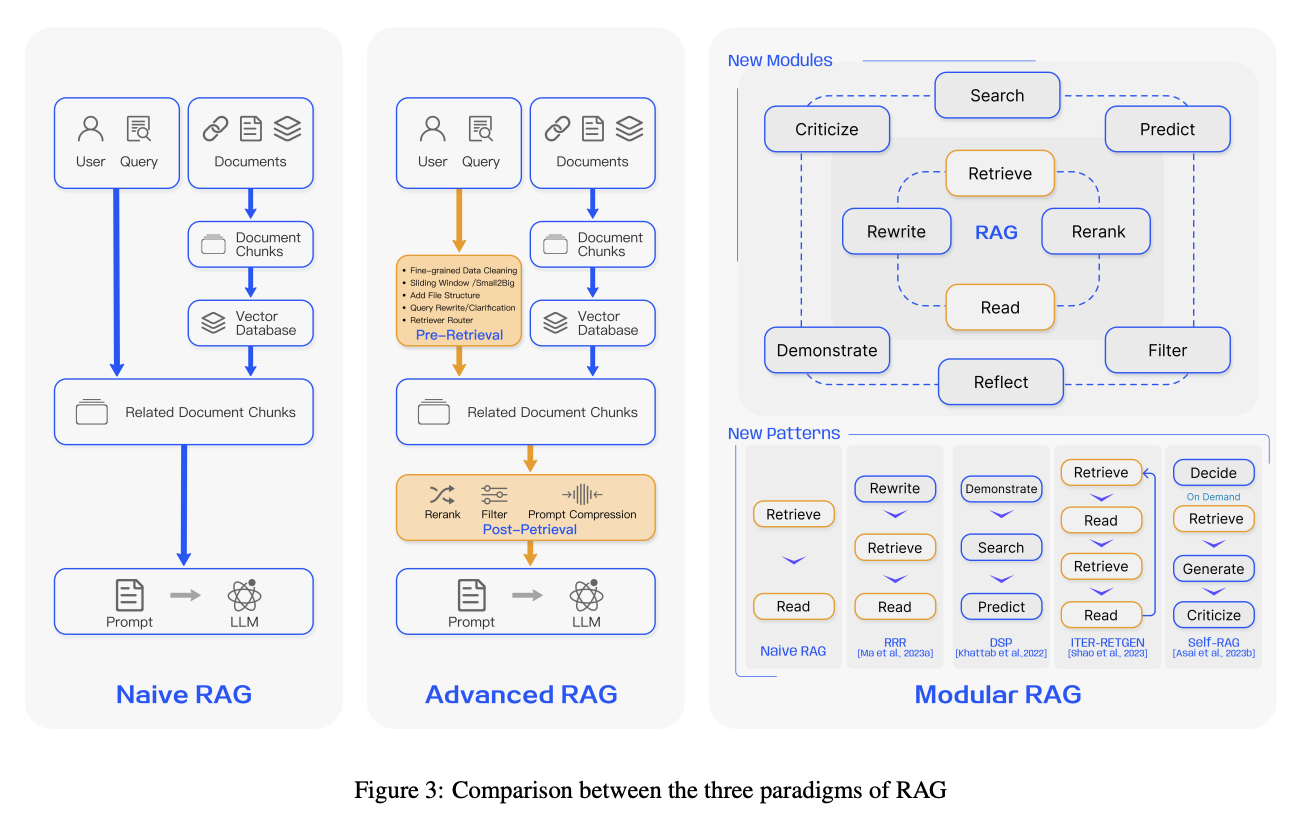
- Naive RAG: 단순 검색 후 답변.
- Advenced RAG: 검색, 구조 보존, Reranking 등 품질 강화.
- Modular RAG: 검색·분석·생성·평가를 모듈로 쪼개 자동화·확장성 확보.
MySQL 5.7에서 MySQL 8.0 으로 마이그레이션하는 방법
🙌 은지님과 유경님의 세미나 🙌
- 은지님과 유경님이 정리한 confluence글
- 기존의 MySQL 5.7은 MySQL 고유 문법을 사용하여 표준 SQL과는 거리가 멀었다.
- 표준 SQL 정의 “ 관계형 데이터베이스에서 데이터를 정의(DDL), 조작(DML), 질의(Query)하기 위한 언어의 공통 규약”
- 모든 DB가 공통으로 이해할 수 있는 기본 문법과 의미 체계인데, MySQL은 표준보단 실용을 우선시 함
- 표준 SQL를 따르는 이유는 호환성과 이식성 때문임 → “DB가 다르더라도 같은 쿼리가 돌아가야 한다” 표준의 존재 이유임.
- => 그래서 MySQL 8.0으로 버전 업데이트 하면서 표준 SQL을 지원함
- Percona XtraBackup: 온라인 백업 가능 (락 거의 없음)
- XtraBackup이 하는 일
- MySQL이 실행 중일 때, InnoDB파일(.ibd, ibdata1) 을 복사
- 그동안 쌓이는 redo log도 실시간으로 읽어서 함께 저장
- 백업 후, redo log를 적용(apply)해서 데이터 정합성을 맞춤.
- 이렇게 하면 실제 DB가 멈추지 않아도 트랜잭션 일관성이 보장된 스냅샷을 만들 수 있음.
- InnoDB 파일 + redo log를 복제
- InnoDB는 트랜잭션을 빠르게 처리하기 위해 데이터를 메모리에 먼저 기록한 뒤 redo log에 “무슨 작업을 했는지”를 남긴다. 그 다음에 나중에 실제 데이터 파일 .ibd에 반영(flush)를 한다.
- 안전하게 롤백이 되었다면, 마이그레이션 진행하기.
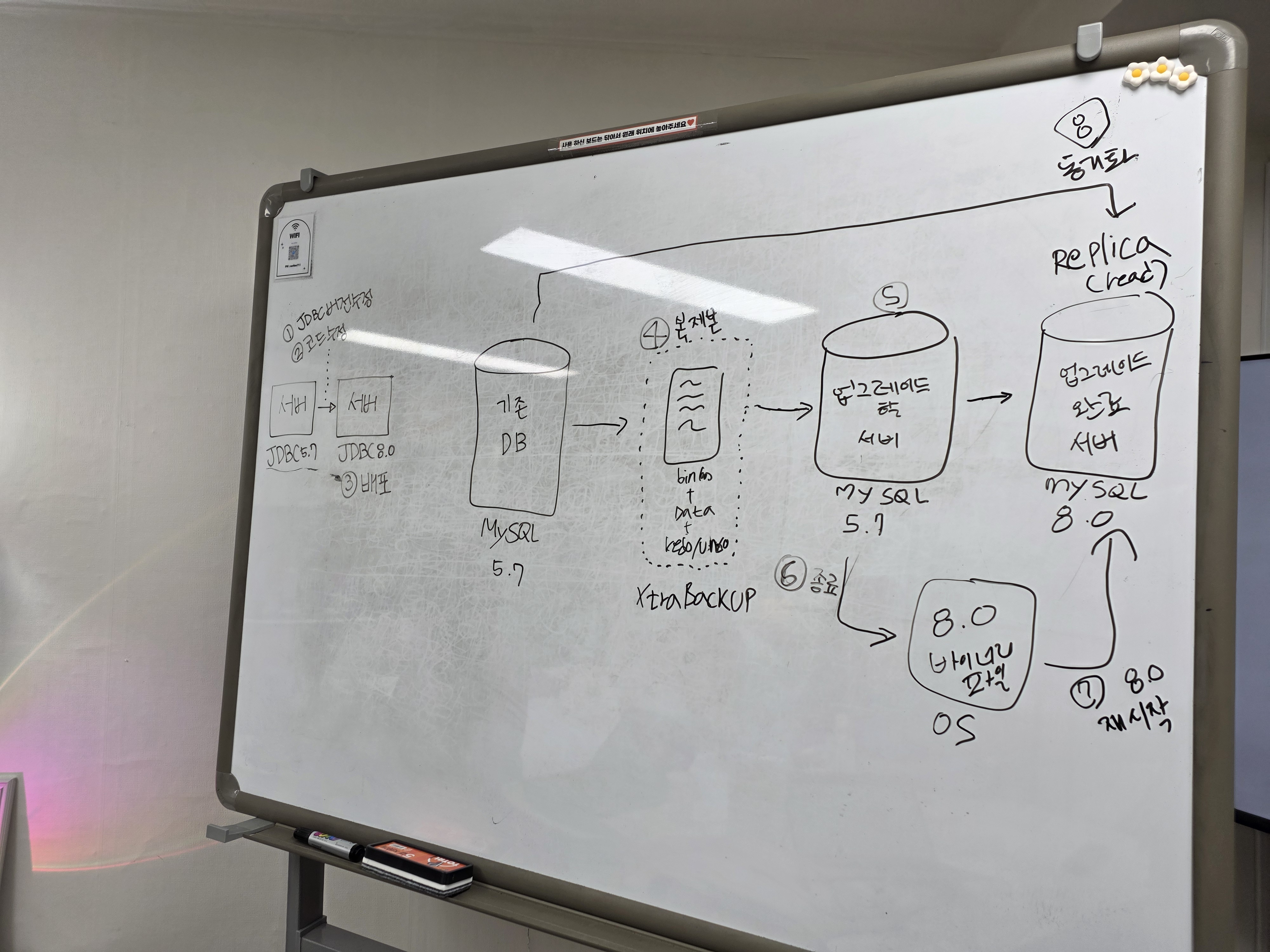
- Percona XtraBackup을 하면서 Replication 기반 Shadow Migration을 진행
- 기존 운영 DB(5.7)를 그대로 두고, 그 데이터를 실시간으로 복제(replication)하면서 새 버전 DB(8.0)으로 동시에 데이터를 동기화 시키는 마이그레이션 방법으로~ 마무뤼~^0^/
Redis 클러스터링이란?
🙌 준호님의 세미나 🙌
- Redis를 RDB처럼 쓰지 않는 이유는 무엇일까 ?
- Redis는 왜 캐시로만 쓸까 ?
- 여기엔 치명적인 이유가 있는데, 우선 기본적으로 Redis는 인메모리다.
- 인메모리 기반이기 때문에 서버를 재시작하게 되면 데이터가 날아간다.
- 물론 Redis 설정에 안날아가도록 하는 설정이 있지만, 그럼에도 불구하고 Redis는 캐시로만 쓴다.
- Redis는 ACID의 C/I/D가 없음
- 메모리 부족 → Eviction 정책 발동으로 인해 데이터 삭제됨
- 속도를 위해 오히려 멀티스레드를 포기한 구조라서 결국 timeout → API 응답 지연 → API timeout이 연쇄적으로 올라가며 시스템 전체 장애 발생한다.
- 트래픽 증가하면서 Redis에 장애 발생하면, “연쇄적으로” 발생할 수 있다.
- 트래픽이 증가면서, 갑자기 Redis 응답이 느려짐
- 애플리케이션에서 timeout 발생
- timeout → retry 로직 동작
- retry로 Redis 요청량이 더 증가
- Redis 더 느려짐
- DB fallback 발생
- DB 과부하
- 전체 API 타임아웃 증가
- API 서버 CPU 증가
- 전체 시스템 장애
이게 바로 Redis(캐시) 장애가 전체 시스템 장애로 번지는 이유다. 이런 장애를 해결하는 방법은 여러가지가 있다.
- ElastiCache Redis – Cluster mode enabled
- 실제 AWS 대규모 서비스가 선택하는 구조.
- 여러 개의 샤드(shard)로 구성
- 각 샤드는 Primary + Replica 구성
- 키(key)에 따라 슬롯(slot)이 자동 분배
- 수평 확장 가능
- Primary 장애 시 Replica로 자동 Failover
- 대량 QPS 처리 가능
- 아래는 AWS에서 말하는 “Redis 클러스터링”이다.
- 애플리케이션이 Redis Cluster 모드 엔드포인트에 접속하면, AWS가 key를 적절한 샤드로 자동 라우팅해준다.
Shard1: Primary + Replica
Shard2: Primary + Replica
Shard3: Primary + Replica
- Single Flight / Request Coalescing
- 여러 요청이 동시에 캐시 미스가 나도 오직 1개의 요청만 DB를 조회하고 나머지 요청은 기다렸다가 결과를 공유하므로써 DB 조회를 1회만 수행한다.
요청 1: 캐시 없음 → DB 조회
요청 2: 캐시 없음 → 요청 1을 기다림
요청 3: 캐시 없음 → 요청 1을 기다림
요청 1 DB 조회 완료 → Redis에 캐시 저장
모든 요청에 캐시 결과 반환
- 서비스별로 Redis를 분리 하는 것이 좋은데, Redis 하나에 여러 기능 붙이면 서로에게 영향을 줄 수 있기 때문이다.
- 캐시
- 세션
- 실시간 카운터
- 랭킹(ZSET)
- 이걸 하나의 Redis에 넣으면 특정 기능의 부하가 전체를 죽을 수 있으니, 아래와 같이 나누는 것이 좋다.
- Redis-cache (TTL 중심)
- Redis-session
- Redis-ranking
- Redis-event-stream